📅 时间: 20:57
🌤️ 天气: 银川 晴10 ~ 21℃ 20
桃未芳菲杏未红,冲寒先喜笑东风。
— 曹雪芹 · 《咏红梅花得“红”字》
现在市面上的模型多如牛毛,各种各样的模型不断出现,LangChain模型组件提供了与各种模型的集成,并为所有模型提供一个精简的统一接口。 LangChain目前支持三种类型的模型:LLMs(大语言模型)、ChatModels(聊天模型)、EmbeddingsModels(嵌入模型)。
- LLMs:是技术范畴的统称,指基于大参数量、海量文本训练的Transformer架构模型,核心能力是理解和生成自然语言,主要服务于文本生成场景
- 聊天模型:是应用范畴的细分,是专为对话场景优化的LLMs,核心能力是模拟人类对话的轮次交互,主要服务于聊天场景
- 文本嵌入模型:文本嵌入模型接收文本作为输入,得到文本的向量。 LangChain支持的三类模型,它们的使用场景不同,输入和输出不同,开发者需要根据项目需要选择相应。
from langchain_ollama import OllamaLLM
# 初始化模型
# 确保你已经在终端运行了: ollama run qwen2.5
model = OllamaLLM(model="qwen2.5")
# 调用模型
res = model.invoke(input="你是谁呀能做什么?")
print(res)流式输出 Streaming
- 流式输出工具函数
from langchain_community.llms.tongyi import Tongyi
def stream_chat_tongyi(user_input, model_name="qwen-max"):
"""
注意:需提前配置环境变量 DASHSCOPE_API_KEY
"""
# 1. 初始化模型
model = Tongyi(model=model_name)
# 2. 调用 stream 方法获取生成器
# 注意:LangChain 新版本建议使用 model.stream(user_input)
res = model.stream(user_input)
# 3. 循环获取并打印结果
print(f"[{model_name} 正在思考]: ", end="")
for chunk in res:
# flush=True 确保文字能实时蹦出来,而不是等缓冲区满了才显示
print(chunk, end="", flush=True)
print("\n" + "-"*20)
if __name__ == "__main__":
stream_chat_tongyi("你是谁呀?能做什么?")end=""
默认的 print 打印完会自动换行,加上这个参数后,光标会停留在这一行末尾,等会儿模型输出的第一个字会紧跟在“正在思考”后面。 for chunk in res: res 在这里不是一个完整的字符串,而是一个生成器。模型每生成一个词(Token),就会把它封装成一个 chunk 发送过来。这个循环就是在“监听”传送带,来一个接一个。
模型对象有2个方法去调用模型:
- invoke,调用模型 一次型返回完整结果
- stream,调用模型 逐段流式输出 这两个方法是新版LangChain(1.0版本后)中基于Runnable接口的通用核心方法。 绝大多数组件(如提示词模板、链、向量检索、工具调用等,后续学习)都支持这两个方法,这也是Lan,gChain设计的核心统一范式。
以前的 LangChain 不同组件调用方式五花八门,现在通过 Runnable 接口,所有的组件都强制实现了相同的“动作”:
- invoke():同步调用。就像函数调用,输入 ,等待处理,返回 。
- stream():流式调用。就像水龙头,打开后数据一块块(chunks)流出来,适合实时交互。
- batch()(补充):批量调用。一次性传一组输入,内部会自动利用并发提升处理效率。
- ainvoke / astream / abatch:这些是对应的异步版本,在开发 [[Django]] 或 FastAPI 等高并发[[后端]]时非常重要。 LangChain 通过定义统一的
invoke和stream规范,实现了: - 解耦:换模型(从本地 Ollama 换到云端 Qwen)不需要改业务逻辑。
- 可组合性:任何实现了接口的组件都能无缝插入工作流。
Runnable
Runnable 接口就是一套“万能插口”协议。 在 LangChain 1.0 之后的版本里,几乎所有的组件(提示词、大模型、解析器)都自带了这个接口。
为什么需要它?(三点核心)
- 统一标准: 不管内部多复杂,所有组件都只有固定的几招:
invoke:像点菜,点完等菜上桌(一次性返回)。stream:像吃自助,边走边拿(流式返回)。batch:像团餐,一次出好几份(批量处理)。
- 极简拼接(LCEL): 因为大家都是一样的插口,你可以用管道符
|把它们无缝串起来:链 = 提示词 | 大模型 | 解析器 - 自动匹配: 只要用了这个接口,LangChain 会自动帮你处理后台的复杂逻辑(比如异步调用、重试机制等),你不需要为每个组件写不同的调用代码。 Runnable 接口把复杂的 AI 组件变成了标准化的“乐高零件”,让q你通过简单的
|就能拼出强大的 AI 工作流。
Chat Models
聊天消息包含下面几种类型,使用时需要按照约定传入合适的值:
- AIMessage:就是AI输出的消息,可以是针对问题的回答。(OpenAI库中的assistant角色)
- HumanMessage:类消息就是户信息,由给出的信息发送给LLMs的提示信息,比如”实现一个快速排序法”(OpenAI库中的user角色)
- SystemMe’ssage:可以用于指定模型具体所处的环境和背景,如角色扮演等。你可以在这里给出具体的指示,比如”作为—个代码专家”,或者“返回json格式”。(OpenAI库中的system角色)
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# 1. 初始化聊天模型
# 注意:确保环境变量 DASHSCOPE_API_KEY 已配置
chat = ChatTongyi(model="qwen-max")
# 2. 构造对话上下文(这就是所谓的“给模型喂记忆”)
messages = [
SystemMessage(content="你是一名来自边塞的诗人"),
HumanMessage(content="给我写一首五言绝句"),
AIMessage(content="大漠孤烟直,长河落日圆。萧关逢候骑,都护在燕然。"),
HumanMessage(content="仿照上一首的格式,自由发挥一首")
]
# 3. 利用 Runnable 接口的 stream 方法流式输出
# 此时 input 接收的是消息列表
for chunk in chat.stream(input=messages):
# 注意:ChatModel 的 chunk 是一个消息对象,内容在 .content 里
print(chunk.content, end="", flush=True)
print("\n" + "-"*20)消息的简写形式
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi(model="qwen-max")
# 简写形式:("角色", "内容")
#(角色,内容) 角色:system/human/ai
messages = [
("system", "你是一名来自边塞的诗人。"),
("human", "写一首唐诗"),
("ai", "锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦。"),
("human", "按照你上一个回复的格式,再写一首唐诗。")
]
for chunk in model.stream(messages):
print(chunk.content, end="", flush=True)system (系统消息):定义AI的身份和行为准则。它是最顶层的指令,决定了AI说话的语气、遵守的规则。例如设定“你是一个只会用Python回答问题的专家”。 human (人类消息):代表真实用户输入。这是对话的主动方,向AI提出问题或发出指令。 ai (AI消息):代表模型之前的回复。在多轮对话中,你必须把AI之前的回答也传回去,模型才知道刚才聊了什么
采用二元元组 是动态的,需要在运行时 由LangChain内部机制转换为Message类对象 好处:
- 由于是动态,需要转换步骤
- 所以简写形式支持内部填充{变量}占位
- 可在运行时填充具体值 后续学习提示词模板时用到
为什么看起来还是要导入不同的包 因为每个模型的底层驱动(SDK)是不一样的。
- 调用通义千问,需要
langchain_community.chat_models.tongyi。 - 调用本地 Ollama,需要
langchain_ollama。 - 调用 OpenAI,需要
langchain_openai。 在软件工程里这叫解耦:你不用为了只用一个通义千问,就把全球几十个大模型的驱动全下载到本地,这样你的项目体积会很精简。
- LangChain 是如何让你“不麻烦”的? 一旦你导入并初始化了模型对象,后面的事情就完全一样了。 这就是我们之前提到的 Runnable 接口。不管你导的是哪个包,代码后面都是:
# 不管你是 chat_tongyi 还是 chat_ollama 还是 chat_gpt4
# 调用的姿势永远统一:
res = chat.invoke(messages)
# 或者
for chunk in chat.stream(messages):
...- 模型工厂模式 如果想更省事,连导入语句都不想改,可以写一个简单的工厂函数。这样你切换模型只需要改一个字符串:
def get_model(provider="tongyi"):
if provider == "tongyi":
from langchain_community.chat_models.tongyi import ChatTongyi
return ChatTongyi(model="qwen-max")
elif provider == "ollama":
from langchain_ollama import ChatOllama
return ChatOllama(model="qwen2.5")
# 业务代码里只需要这一行,想换模型改个参数就行
chat = get_model("ollama")
chat.invoke("你好")- init_chat_model LangChain 最近推出了一个更省事的实验性功能
init_chat_model,它试图让你连具体的类名都不用记:
from langchain.model_laboratory import init_chat_model
# 只需要传模型名,它会自动帮你去后台找对应的包
model = init_chat_model("qwen-max", model_provider="tongyi")Embeddings Models 文本嵌入模型
EmbeddingsModels嵌入模型的特点:将字符串作为输入,返回一个浮点数的列表(向量)在NLP中,Embedding的作用就是将数据进行文本向量化。 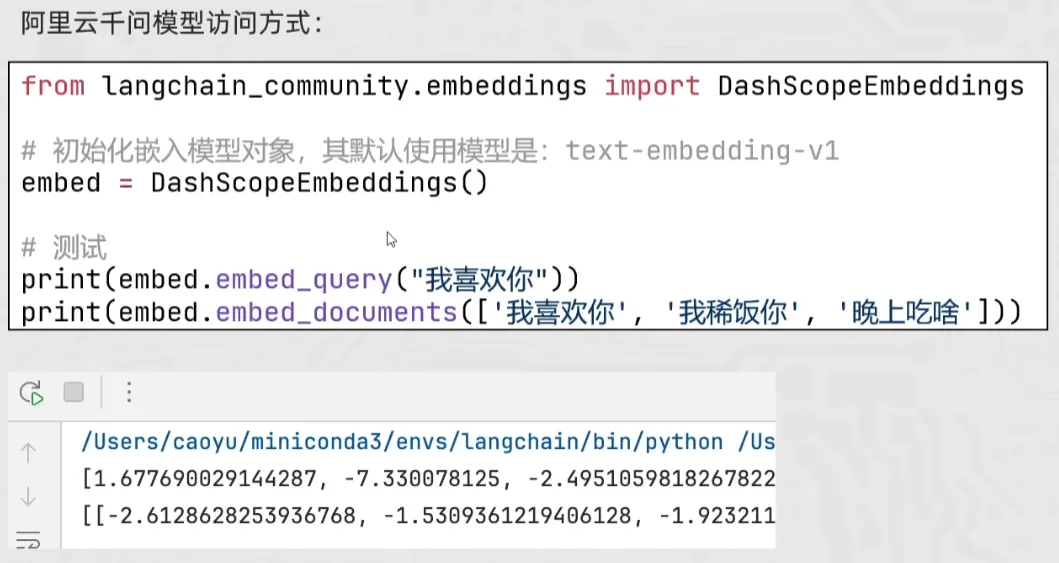
本地ollama模型访问方式: 通过langchain_ollama导入ollamaEmbeddings使用,其余不变。
from langchain_ollama import OllamaEmbeddings
embed = OllamaEmbeddings(model="qwen3-embedding")
print(embed.emb_query("111"))
print(embed.embed_documents(['1','2','3']))
OllamaEmbeddings 提供了两个标准接口,分别处理单条查询和多条文档:
embed_query(text):用于转化用户的提问。它接收一个字符串,返回一个浮点数列表(向量)。embed_documents(list):用于转化待检索的文档片段。它接收一个字符串列表,返回一个嵌套的向量列表。
OllamaEmbeddings提供了两个标准接口:embed_query(text)用于转化用户的提问,接收字符串并返回浮点数列表(向量);embed_documents(list)用于转化待检索的文档片段,接收字符串列表并返回嵌套向量列表。 embed_query(text):专门处理用户的提问,输入字符串,输出单个向量。 embed_documents(list):批量处理知识库文档,输入列表,输出多个向量。
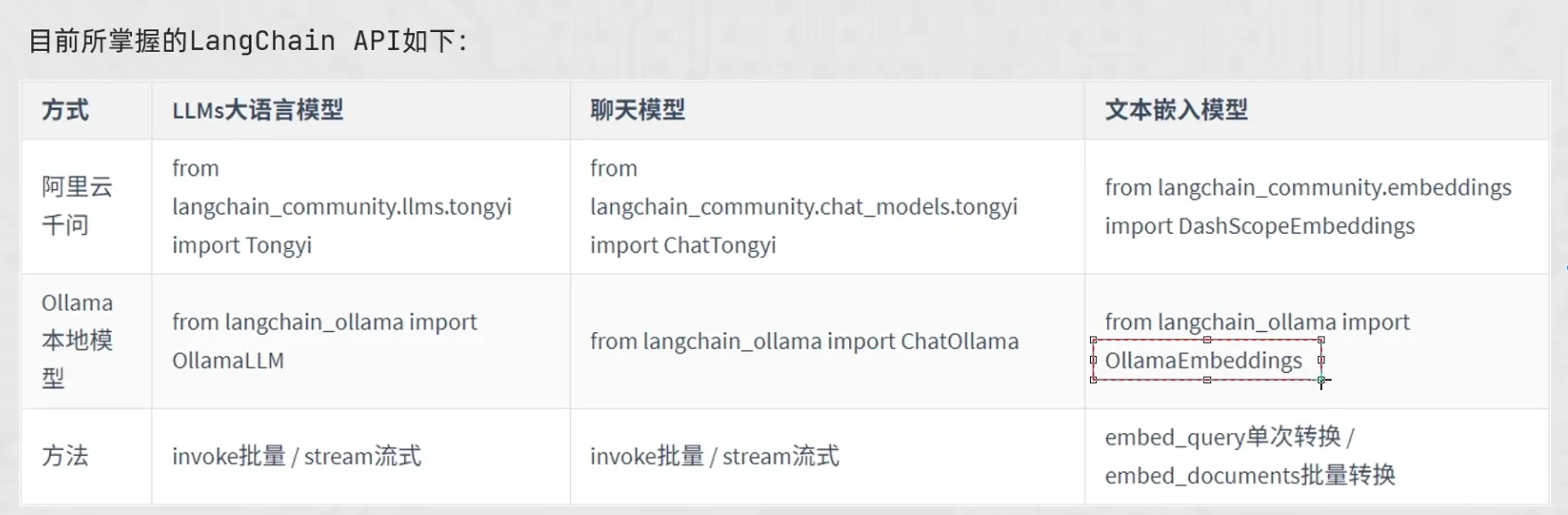
模型使用总结
通用prompt
提示词优化在模型应用中非常重要,LangChain提供了PromptTemplate类,用来协助优化提示词。 PromptTemplate表示提示词模板,可以构建一个自定义的基础提示词模板,支持变量的注入,最终生成所需的提示词。
from langchain_core.prompt import PromptTemplate
from langchain_community.llms.tongyi import Tongyi
# lastname = "张"gender="女儿"
# s=f"我的邻居姓{lastname},刚生了{gender},你帮我起个名字,简单回答。"
# 字符串这种写法加入不到chain中,因为
prompt_template = PromptTemplate.from_Template(
"我的领居姓{lastname},刚生了{gender},你帮我起一个名字,简单回答一下"
)
# 调用format
prompt_text = prompt_template.format(lastname="张",gender="女儿")
model = Tongyi(model="qwen-max)
res = model.invoke(input = prompt_text)
print(res)
#另一种 chain链
chain = prompt_template | model
res = chain.invoke(input = {"lastname":"张","gender":"女儿"})
print(res)为什么 f-string 无法加入 Chain 字符串是静态数据,不是 Runnable 对象。管道符要求连接的组件必须具备处理流的能力。
- 变量已固化:f-string 在定义时就立刻解析了变量。一旦生成,它就变成了一段普通文本。而 Chain 需要的是一个模板,它像一个函数,等待在运行阶段动态接收数据。 f-string 就像是一碗已经煮好的熟饭。当你写下 s = f”姓{lastname}” 的瞬间,Python 就已经把变量填进去,得出了最终的字符串结果。s 现在就是一个死板的、不能再变的文本。它不具备接收新数据的能力。 PromptTemplate 就像是一个电饭煲。它本身不是饭,而是一个煮饭的逻辑。它在代码里静静等待,只要你以后给它不同的米(变量),它就能按照预设的规则产出不同的饭(字符串)。
- 缺少调用接口:LangChain 组件都必须有 invoke 等方法。Python 的字符串类型没有实现这些接口,所以它不知道如何把内容传递给管道里的下一个节点。
- 为什么 Chain 需要电饭煲(Template)? Chain 是一条自动化的流水线,它的核心是管道符 |。水管要求每一节都必须能接水、处理水、再把水传给下一节。 f-string 是一瓶封死的水:它已经成型了,没法再接收上游传来的变量,所以它接不进水管里。 Template 是一个水泵:它在管道里等着。当你往 Chain 的入口丢进一个字典数据时,Template 会立刻把数据填进模板,生成文本并推给下游的模型。 基于PromptTemplate类可以得到提示词模板,支持基于模板注入变量得到最终提示词。 zero-shot思想下,可以基于PromptTemplate直接完成。few-shot思想下,需要更换为FewShotPromptTemplate (后续学习) PS:使PromptTemplate还不如拼接字符串? 使用Template模板构建提示词,在大型工程中更容易做标准化模板Template模板类,支持LangChian框架的链式调用(Runnable接口,后续学习) .PromptTemplate •FewShotPromptTemplate(后续学习)ChatPromptTemplate(后续学习)
FewShotPromptTemplate
from langchain_core.prompts import FewShotPromptTemplate
template = FewShotPromptTemplate(
examples=None,
example_prompt=None,
prefix=None,
suffix=None,
input_variables=None
)FewShotPromptTemplate 核心参数
- examples: 示例数据。格式为 list,内套字典(例如:
[{"input": "xxx", "output": "xxx"}])。 - example_prompt: 示例数据的提示词模板。用于格式化每一个具体的 example。
- prefix: 组装提示词时的前缀。通常放在所有示例数据之前的内容。
- suffix: 组装提示词时的后缀。通常放在所有示例数据之后的内容(常包含最终的用户输入变量)。
- input_variables: 变量列表。整个提示词模板中需要注入的变量名列表。
from langchain_core.prompts import PromptTemplate,FewShotPromptTemplate
#调用模型
from langchain_community.llms.tongyi import Tongyi
example_template = PromptTemplate.from_template("单词:{word},反义词:{antonym}")
example_data = [
{"word":"大","antonym":"小"},
{"word":"上","antonym":"下"},
]
# FewShotPromptTemplate(example_prompt=None,examples=None,prefix=None,suffix=None,input_variables=[])
FewShotPromptTemplate(
example_prompt=None, #示例数据的模板
examples=None, #示例的数据(用来注入动态数据的),1ist内套字典
prefix=None, #示例之前的提示词
suffix=None, #示例之后的提示词
input_variables=[] #声明在前缀或后缀中所需要注入的变量名
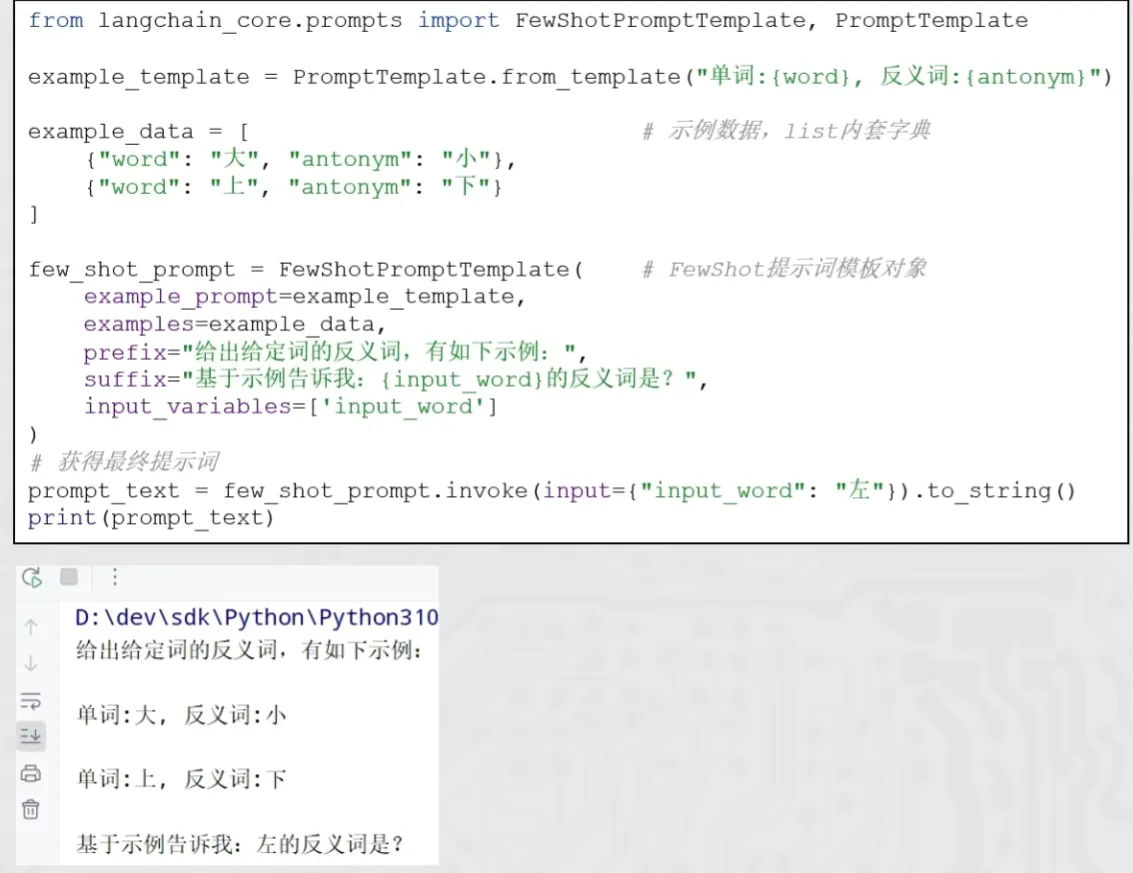
)from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_community.llms.tongyi import Tongyi
# 1. 定义单个例子的格式
example_template = PromptTemplate.from_template("单词: {word}, 反义词: {antonym}")
# 2. 准备示例数据
examples_data = [
{"word": "大", "antonym": "小"},
{"word": "上", "antonym": "下"}
]
# 3. 配置少样本模板
few_shot_template = FewShotPromptTemplate(
examples=examples_data,
example_prompt=example_template,
prefix="告知我单词的反义词,我提供如下的示例:",
suffix="基于前面的示例告知我,{input_word}的反义词是?",
input_variables=["input_word"]
)
# 4. 生成最终提示词并调用
prompt_text = few_shot_template.invoke({"input_word": "左"}).to_string()
model = Tongyi(model="qwen-max")
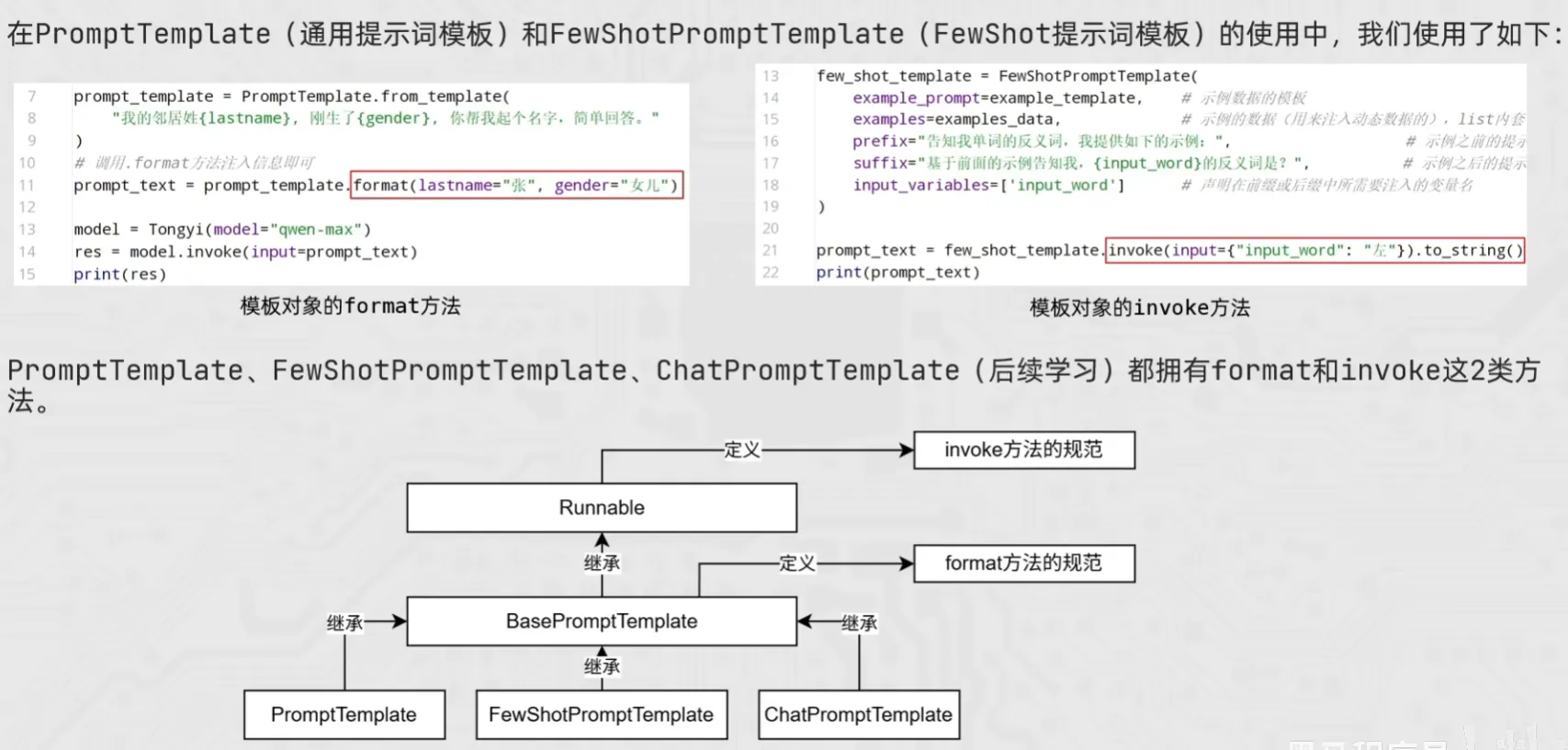
print(model.invoke(input=prompt_text))模板类的format和invoke方法
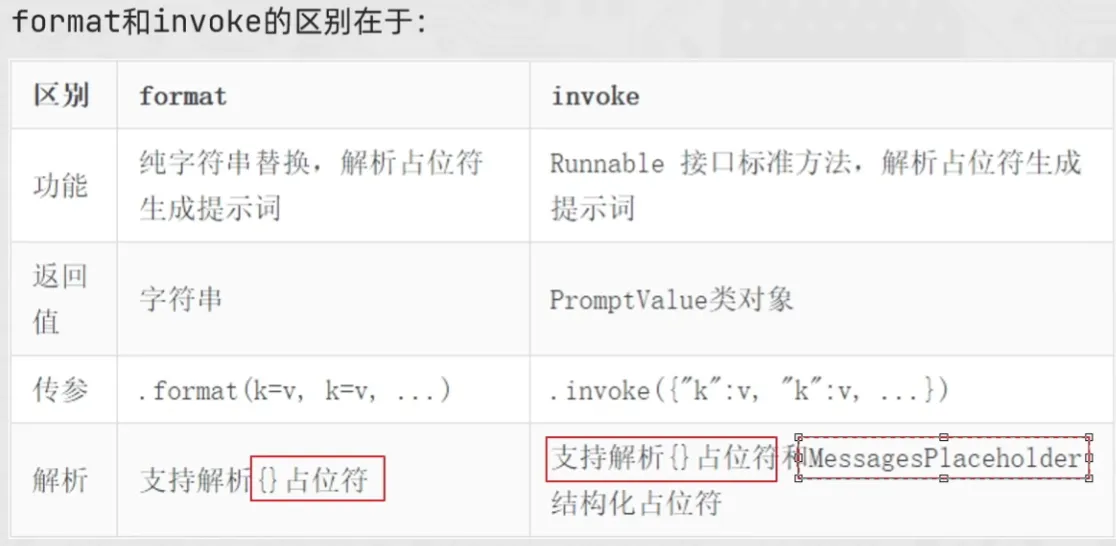
from langchain_core.messages import AIMessage
from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import FewShotPromptTemplate
from langchain_core.prompts import ChatPromptTemplate
"""
继承关系背后的逻辑:
PromptTemplate -> StringPromptTemplate -> BasePromptTemplate -> RunnableSerializable -> Runnable
FewShotPromptTemplate -> StringPromptTemplate -> BasePromptTemplate -> RunnableSerializable -> Runnable
ChatPromptTemplate -> BaseChatPromptTemplate -> BasePromptTemplate -> RunnableSerializable -> Runnable
"""
# 1. 实例化模板
template = PromptTemplate.from_template("我的邻居是: {lastname}, 最喜欢: {hobby}")
# 2. 传统格式化方式:返回纯字符串 (str)
res = template.format(lastname="张大明", hobby="钓鱼")
print(res, type(res))
# 3. 链式调用接口方式:返回 StringPromptValue 对象
# 只有实现了 Runnable 接口,才能使用 invoke,也才能接入 | 管道符
res2 = template.invoke({"lastname": "周杰伦", "hobby": "唱歌"})
print(res2, type(res2))ChatPromptTemplate
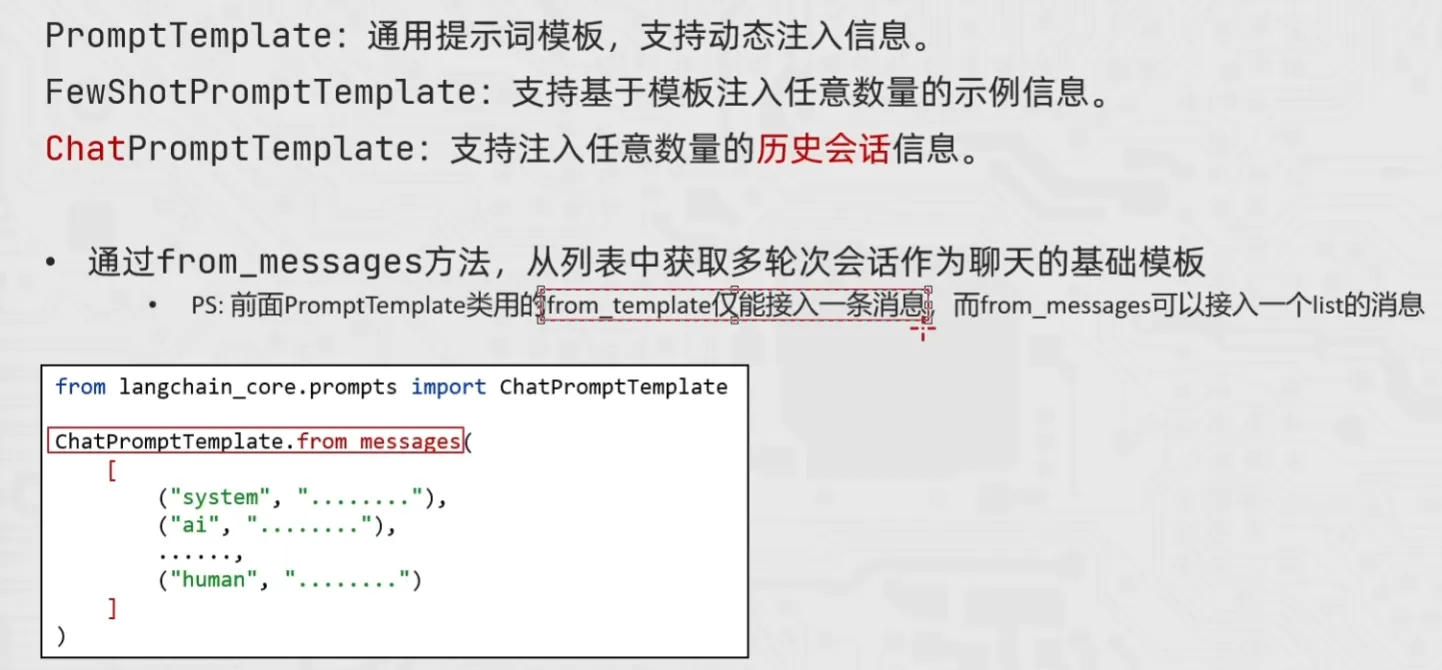
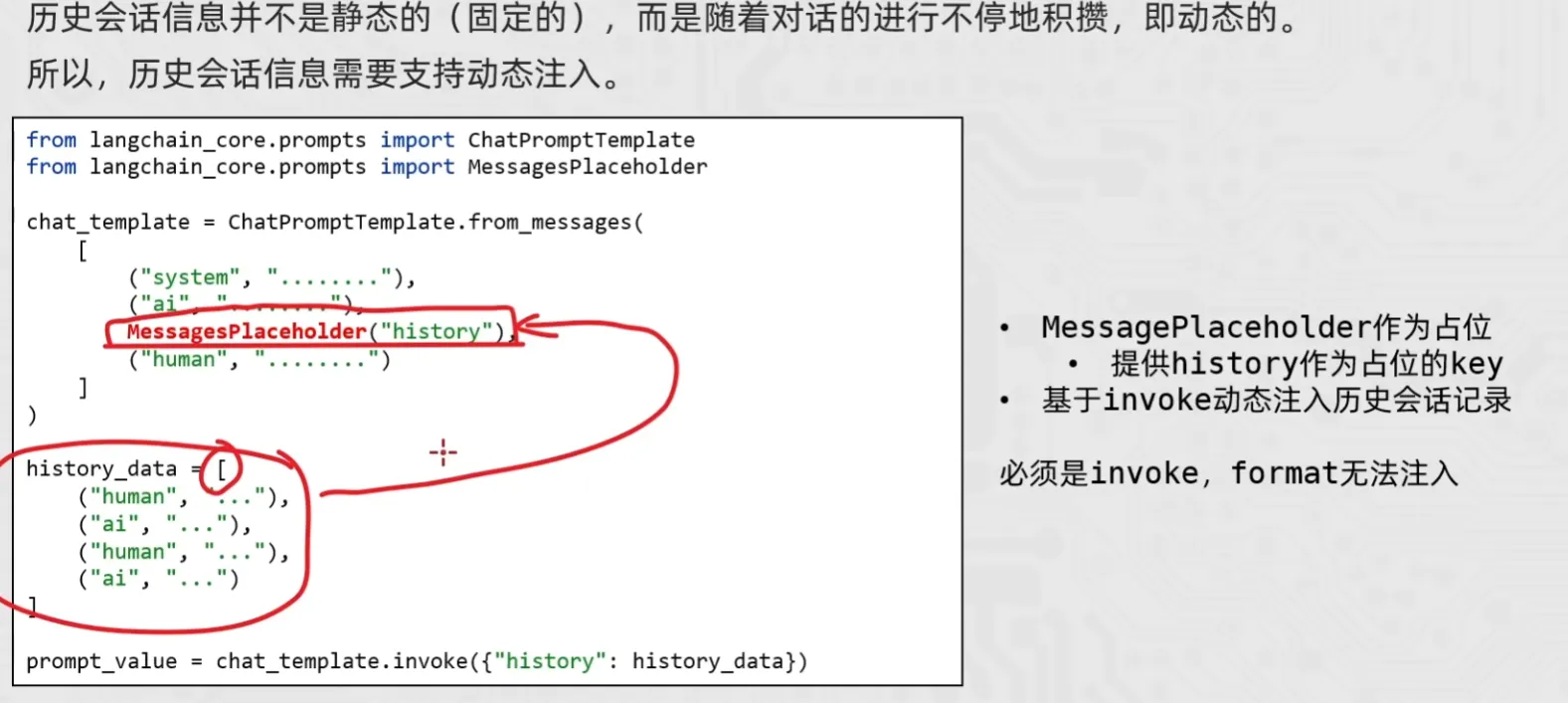
chain链
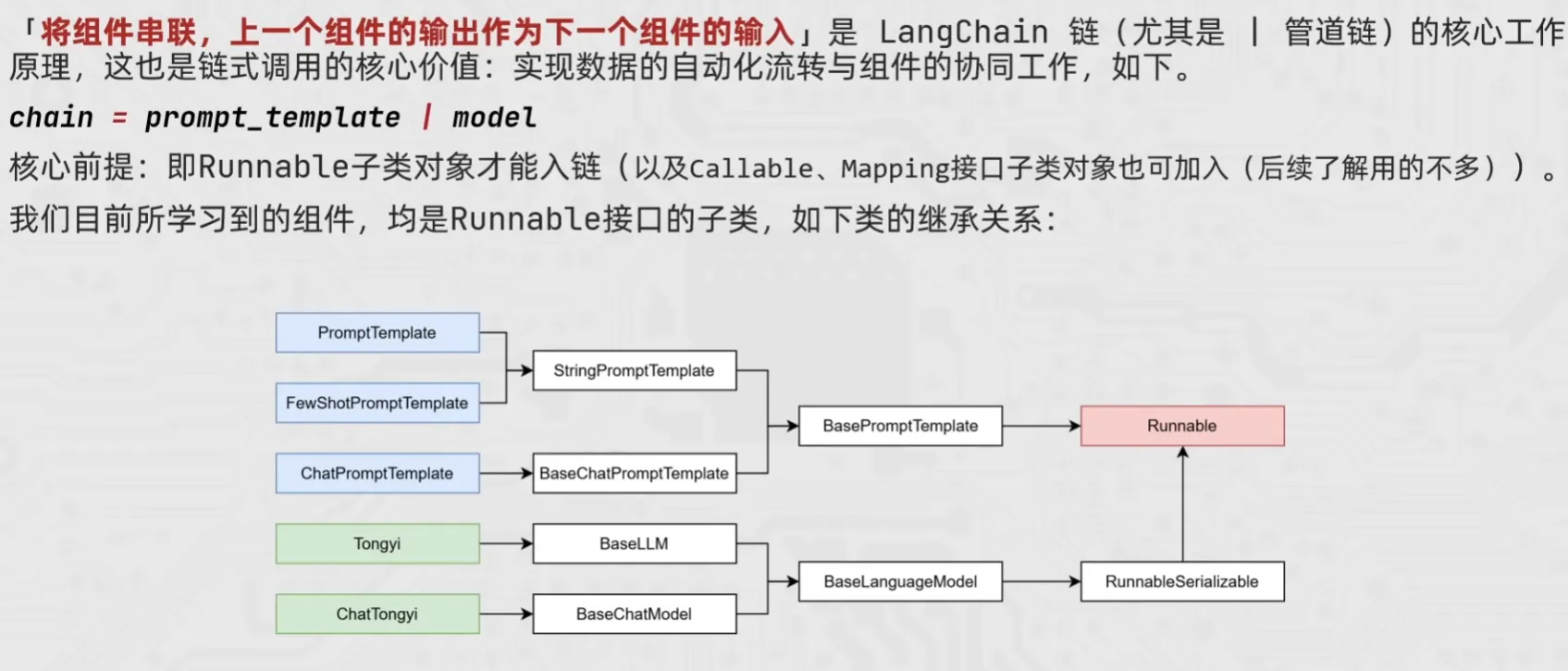
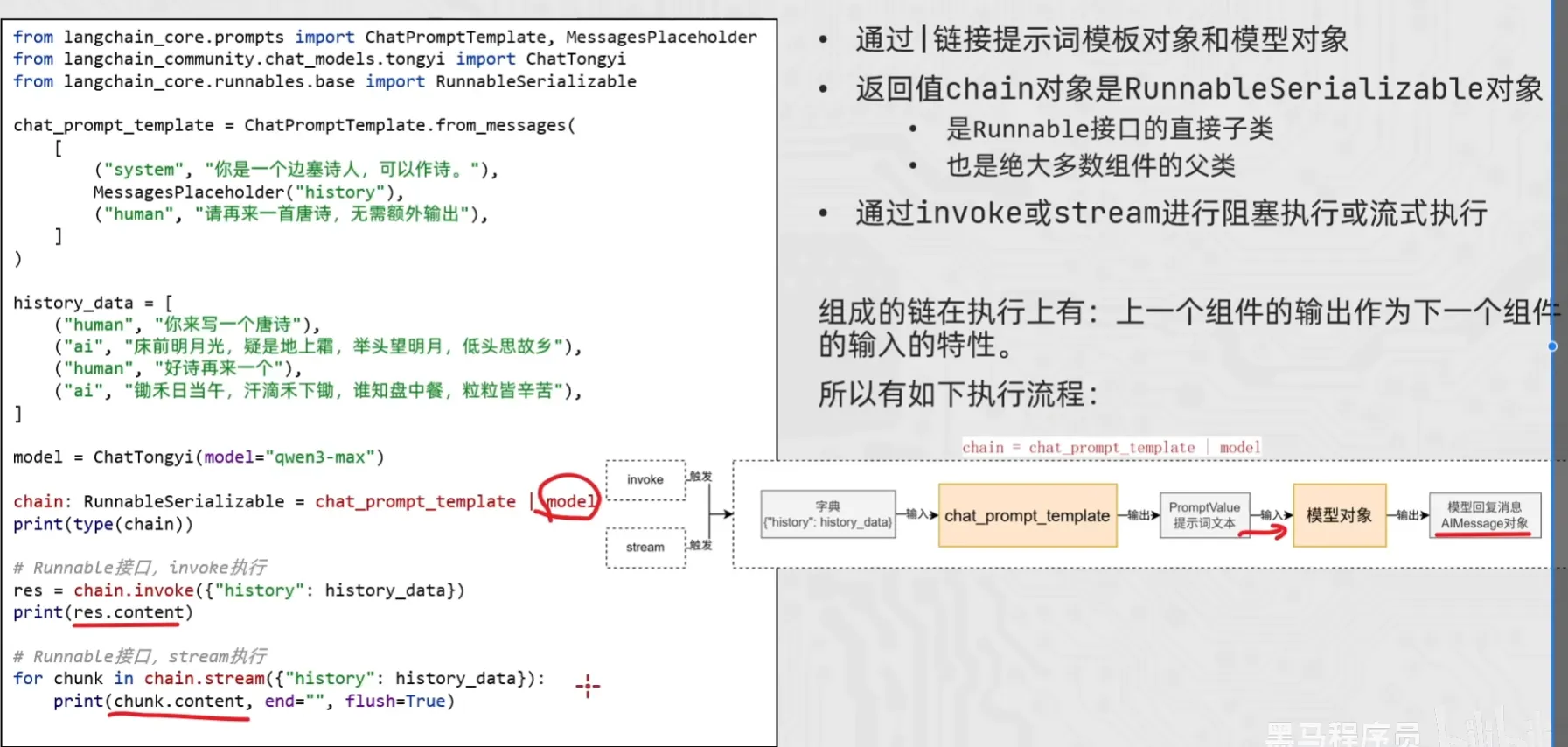
 LangChain 链(Chain)核心逻辑总结 这段内容揭示了 LangChain 实现自动化工作流的底层机制。所谓的“链”,本质上就是一套基于 Runnable 协议的“工业流水线”。
LangChain 链(Chain)核心逻辑总结 这段内容揭示了 LangChain 实现自动化工作流的底层机制。所谓的“链”,本质上就是一套基于 Runnable 协议的“工业流水线”。
- 核心表现形式:管道符 | 在代码中,| 不再是位运算,而是逻辑连接符。 它将上一个组件的输出,自动解包并传递给下一个组件作为输入。这种写法被称为 LCEL (LangChain Expression Language)。
- 准入条件:Runnable 接口 不是所有对象都能成链。 只有继承了 Runnable 接口的类(如 PromptTemplate, ChatModel, OutputParser)才能参与串联。因为这些类都实现了统一的方法(如 invoke),保证了组件之间“接口对齐”。
- 链的本质:RunnableSerializable 当你把多个组件用 | 连起来后,生成的整个 chain 对象本身也是一个 RunnableSerializable(即 Runnable 的子类)。 这意味着:链也可以嵌套链。你可以把一小段链当成一个整体,再去连接其它的组件。
- 触发机制 链是“懒加载”的,定义好了不会自动执行。 invoke:单次触发。你喂给它初始数据,它跑完整个流程后吐出最终结果。 stream:流式触发。它会一边处理一边往外吐数据块(比如 AI 逐字回复的效果),这在做 Web 端交互时体验最好。
- 为什么要在项目里这么写? 高度解耦:如果你想把通义千问换成 GPT,只需把管道里的 [[model]] 变量改一下,前后逻辑完全不用动。 自动并行:LangChain 内部优化了 Runnable 接口,如果链中某些步骤不互相依赖,它会自动尝试并行处理,提升效率。